
Description
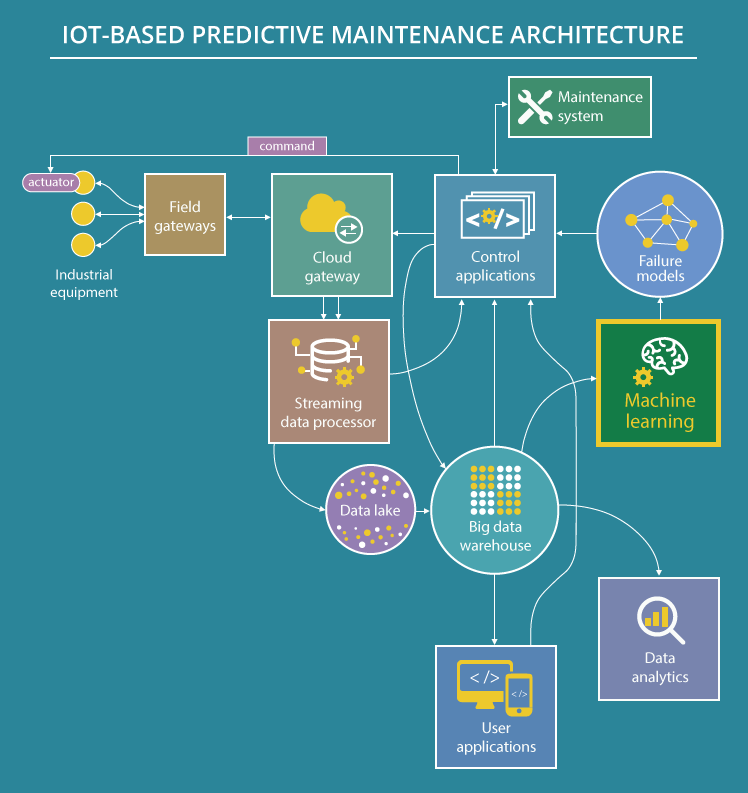
Server downtime can lead to significant disruptions, revenue losses, and decreased customer satisfaction. Our Predictive Maintenance Model for Server Clusters is designed to proactively identify potential hardware failures before they impact your business. Using advanced machine learning algorithms, this service continuously analyzes server performance metrics—such as CPU temperature, disk I/O rates, memory usage patterns, fan speed, and power draw—to detect anomalies and signal early warnings. The model learns from historical data to identify patterns associated with previous failures and creates predictive alerts when similar trends are detected. This enables IT teams to act in advance, scheduling maintenance, replacing parts, or redistributing workloads—without reactive firefighting. We use technologies like Python (scikit-learn, XGBoost, TensorFlow) and integrate telemetry feeds via SNMP, Prometheus, or vendor-specific monitoring tools. Our system supports clustering and ensemble methods to increase prediction accuracy, as well as real-time dashboards for monitoring KPIs and upcoming risks. Integration with platforms like Nagios, Zabbix, Datadog, or custom DevOps pipelines ensures seamless operation within existing environments. By transitioning from reactive to predictive maintenance, enterprises significantly reduce unplanned downtime, optimize server utilization, and extend the lifecycle of their infrastructure—all while improving ROI.

Tukur –
The predictive maintenance model for our server clusters has been a significant improvement to our IT infrastructure management. The ability to proactively identify potential hardware issues through machine learning and real-time data analysis has allowed us to schedule maintenance efficiently, minimizing disruptions and preventing costly unplanned outages. This has resulted in greater system reliability, reduced operational expenses, and a noticeable extension of our server lifespan.
Uba –
The predictive maintenance model for our server clusters has been a resounding success. The ability to anticipate hardware issues based on machine learning and real-time data has significantly reduced unexpected downtime. We’ve seen a noticeable improvement in the lifespan of our equipment and a marked optimization of our IT operations. This proactive approach has transformed our maintenance strategy and provided considerable peace of mind.